LangChain Vector Store Queries
Built-In Parameters of Large Language Models
{kind=link}
Much has been said about LLM parameters and how they determine text completions. Under the hood, LLMs are made of interconnected neural network nodes organized into layers. During LLM training, the network learns from training data and weights are assigned to the connection between the nodes. Through a series of forward and back propagation, these weights are optimized to improve the LLM’s performance, enabling it to make accurate predictions. Along with the quantity and quality of the training data, plus hyperparameters that can be fine-tuned to improve the LLM performance on specific tasks, these interconnection weights represent the parameters of the LLM.
Augmenting with Non-Parametric Knowledge
Vector stores are one way to extend a model with non-parameteric data. By means of embeddings – words, subwords and characters represented in continuous vector space – we add domain-specific information to the knowledge store of the LLM, helping it to respond to a wider range of queries with more relevant text completions.
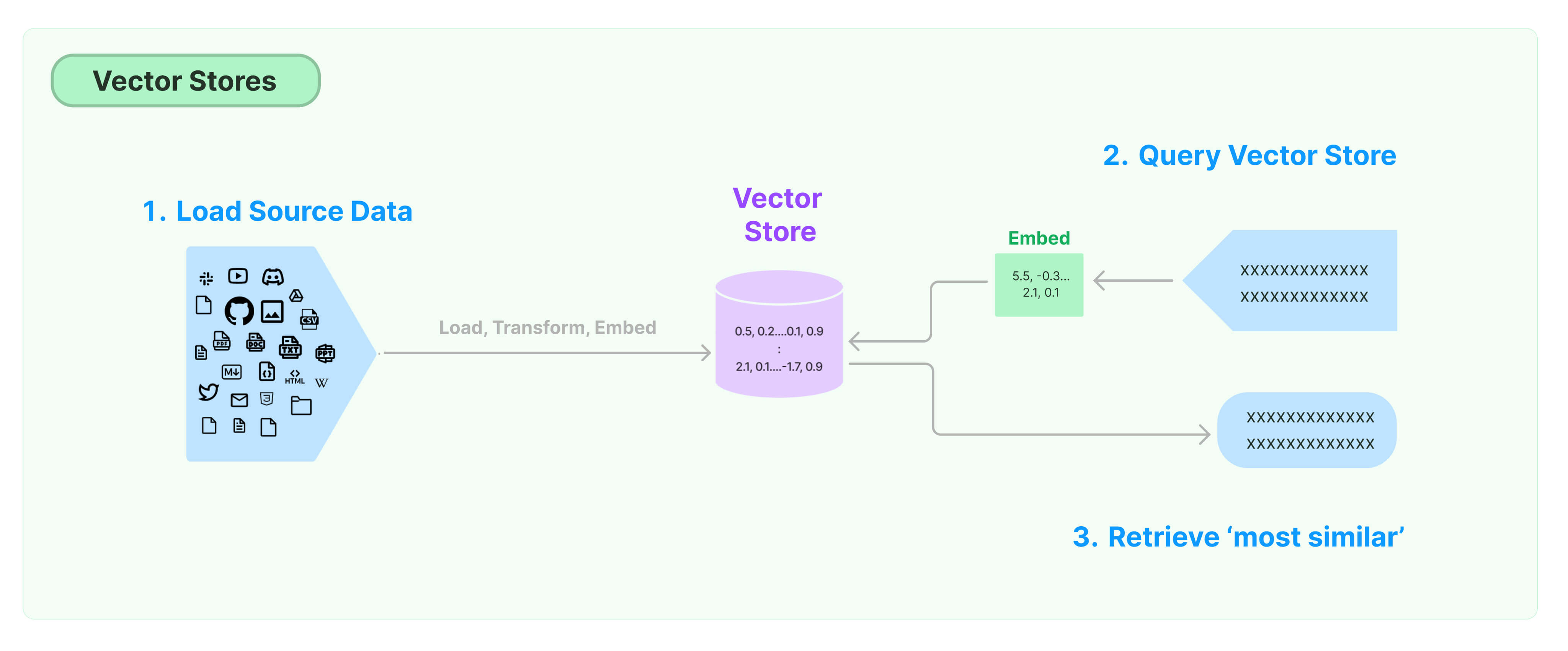
In LangChain, three embedding components come into play. All three are integrated into an embedding vector store.
- An embedding model
- Source data (multiple-text) embedding
- User query (single input text) embedding
In the next section, we’ll present a working example of Python-LangChain vector store queries that illustrates each of these three components.
Vector Store Queries Using Python-LangChain
The key to extending a LLM with non-parametric knowledge lies with the embedding model of a vector store. An embedding model is a vector representation of information. In a natural language context, these numerical values capture the context and relationship of words. As part of a vector store, the embedding model re-purposes the pre-trained model by supporting the inclusion of new data sets, in this case the source and user query texts.
This AWS article on deep learning model embeddings explains its use in machine learning.
The two files that are part of this small project show how we can work with LangChain vector stores to query domain-specific data store. One of these files is the source data, a chatlog of a customer’s experience with Lufthansa Airlines.
We are flying Lufthansa premium economy from Charlotte to Munich in Sept.
Has anyone else flown with them in this class?
If so can you review the experience.
I paid $200 extra for each seat from Charlotte to Munich but had to pay $500 extra for each seat on the way home from Munich to Charlotte.
Not sure why this huge disparity but was essentially told by Lufthansa "we do so because we can".
Thanks for your response in advance....The chatlog used here is a single entry in a large data set provided for free by the Kaggle user Veeralakrishna.
The second file in this project is our Python script. Inspecting the imported LangChain modules we see a run down of the architectural components a vector store is made of.
LangChain integrates numerous vector stores from third party providers.
- Text loaders and formatters to handle the data source embeddings
- Embedding model courtesy of OpenAI
- Facebook AI Similarity Search (FAISS) vector store
- Query modules to run the list of single query embeddings
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
langchain-openai-vectorstorequery.py script and the source data langchain-openai-luftairchatlog.txt. The set of individual queries are part of the Python script. Alternately, here is the Jupyter notebook for this project.
The next relevant block of code feeds the FAISS emebdding model and the source data (mutiple line text) into our vector database. The source data is none other than the short chatlog of a Lufthansa Air customer shown above.
raw_documents = TextLoader('LuftAir_chatlog.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=200,
chunk_overlap=0,
separator="\n",)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())Finally, our script walks through a list of queries (single input text). The output of the LangChain query retriever is shown below. Note the nuanced answers the model gives on questions designed to trip it (see Cebu flight inquiry).
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=retriever
)
query_list = [
"What airline was being discussed?",
"Which city did the flight depart from?",
"Did they fly economy class?",
"How much was paid for an extra seat from Charlotte?",
"How much was paid for an extra seat from Munich?",
"How much was paid for an extra seat from Cebu?",
"Did the passenger enjoy her flight?"
]{'query': 'What airline was being discussed?', 'result': ' Lufthansa'}
{'query': 'Which city did the flight depart from?', 'result': ' The flight departed from Charlotte.'}
{'query': 'Did they fly economy class?', 'result': '\nIt is not specified in the given context whether they flew economy class or not. However, it is mentioned that they paid extra for premium economy seats.'}
{'query': 'How much was paid for an extra seat from Charlotte?', 'result': ' $200 extra for each seat from Charlotte to Munich.'}
{'query': 'How much was paid for an extra seat from Munich?', 'result': ' $500'}
{'query': 'How much was paid for an extra seat from Cebu?', 'result': " I don't know. The context given does not mention anything about Cebu or the cost of an extra seat from there."}
{'query': 'Did the passenger enjoy her flight?', 'result': ' I do not know.'}