Ollama Serving Llama3.1 Over HTTP
Introduction
Since its July 10, 2023 preview release on GitHub, Ollama has become a compelling framework for deploying large language models. An ecosystem of extensions, packages and libraries have sprung up around it, making Ollama a useful tool for the developer working on LLM client-server applications.
This succinct article goes through the installation and configuration of Ollama on a local machine. It then presents a short Python script to confirm the deployment. Notably, the article describes a method using a JSON file to configure Ollama’s run time behavior. In contrast, I simply use environment variables.
To get myself handy with Ollama, I conceived a toy application in which a command line program would interact via HTTP with llama3.1 hosted within an Ollama container. Here we roll out a simple NLP task that is a variant of the question-and-answer use case for LLMs. We ask llama3.1 to enumerate Catholic saints born in Italy.
When the Saints Go Marching In#
Apart from its curate, its liturgy and the architecture of its churches, nothing speaks of the Catholic Church as does its impressive roster of martyrs and saints. It’s no surprise that, based on a quick survey, the greatest number of Catholic saints are clustered around two countries: Italy and Spain.
As a proof of concept, I set about writing a simple C++ client to retrieve a list of saints born in Italy, asking 1lama3.1 8.0B to serve up the data.
#A nod to Louis Armstrong’s famous Christian hymn. The song’s origin is discussed here.
Why not host Ollama in the Linux virtual machine? The answer: disk requirements of a large large model. There are other overriding reasons, but llama3.1 8B takes up a large disk space, nearly 5GB, which makes installing it together with Ollama in the Linux virtual host impractical. In the long run, because I hope to deploy other LLMs hosted by Ollama on my PC, it makes more sense to keep the Ollama stack in the Windows system.
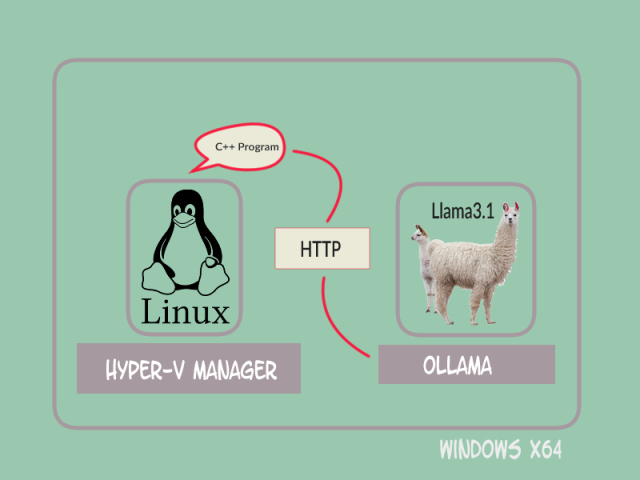
Once it receives a request from the client application, the Ollama module relays the request to the encapsulated llama3.1 LLM, then replies with a list of record with the data for each Italian saint. A data record is laid as follows:
| Name | Place of Birth | Place of Death | Year of Birth | Year of Death |
Below is a sample output showing the first few records.
Hello, Ollama! Connecting to server http://<IP address>:<port #>
Here is the list of Italian Roman Catholic saints:
1. **Agnes of Assisi** | Assisi, Italy | Unknown | unknown | 1253
2. **Ambrose of Milan** | Trier, Germany (but lived in Milan, Italy) | Milan, Italy | unknown | 397
3. **Anastasia of Sirmium** | Sirmium, Pannonia (now Sremska Mitrovica, Serbia, but considered Italian due to her association with the city of Ravenna) | Bari, Italy | unknown | 304
4. **Antoninus of Florence** | Piacenza, Italy | Florence, Italy | 923 | 1012
5. **Apollonia of Rome (Italian tradition)** | Alexandria, Egypt (but considered Italian due to her association with the city of Ravenna) | Alexandria, Egypt (but died in Ravenna, Italy) | unknown | 249
6. **Aquilinus of Piacenza** | Piacenza, Italy | Piacenza, Italy | unknown | 430
7. **Arnold of Soana** | Soana, Italy | Rome, Italy | 1174 | 1257
8. **Attilanus of Naples** | Naples, Italy | Naples, Italy | unknown | 305The C++ client program is short and straight forward.
#include <iostream>
#include <string>
#include "ollama.hpp"
int main(int argc, char** argv) {
const char* llm_query = "You are a helpful assistant who creates a comprehensive list "
"of Roman Catholic saints only from Italy. Format you output as: "
"FULL NAME | PLACE OF BIRTH | PLACE OF DEATH | YEAR OF BIRTH | YEAR OF DEATH. "
"No need to state their \'Saint\' title. Include saints with information marked "
"\'unknown\'. ";
if (argc < 2) {
std::cerr << "Usage: ItalianSaints_01 <Ollama server URL>" << std::endl;
std::cerr << " $> ./ItalianSaints_01 http://<server IP address>:<port#>" << std::endl;
return -1;
}
std::string llm_url = argv[1];
std::cout << "Hello, Ollama! Connecting to server " << llm_url << std::endl;
Ollama my_server(llm_url);
ollama::options llm_options;
llm_options["top_p"] = 1;
llm_options["temperature"] = 0;
llm_options["frequency_penalty"] = 0;
llm_options["presence_penalty"] = 0;
llm_options["repetition_penalty"] = 1;
llm_options["top_k"] = 0;
ollama::response llm_answer = my_server.generate("llama3.1", llm_query, llm_options);
std::cout << llm_answer << std::endl;
return 0;
}Here is the Gnu C++ call for compiling the program.
The ollama-hpp repository is hosted at GitHub. To compile this toy project, I simply copied the header files from the include folder of the repository for g++ to use.
g++ ItalianSaints_01.cpp -I../ollama-hpp/include -std=c++11 -o ItalianSaints_01Client and Server Working in Tandem
The Ollama project makes it easy to get the server program up and running. In a Windows host environment the steps are straightforward.
Port 11434 is the canonical network port Ollama listens to but any valid and available port is allowed.
# Get the IP address of the host computer
$> ipconfig
# Set the Ollama server IP and listening port
$> $Env:OLLAMA_HOST='<ip address>:<port #>'
# Start the Ollama server
$> ollama run llama3.1curl comes in handy to confirm the server is ready.
$> curl http://<server IP>:<port #>/api/generate -d
'{
"model":"llama3.1",
"prompt":"Who are you?",
"streaming": false
}'A reply from the LLM to the prompt indicates that Ollama is up and running.
On the client side, after compiling the C++ code, the program can connect with the server and fetch the list of Italian Catholic saints as per our prompt to llama3.1.
$> ./ItalianSaints_01 http://<server IP address>:<port #>And that is that! Written in golang, Ollama has client APIs in several programming languages, speaking REST and JSON underneath it all.