The Colab-Hugging-Face-Llama3.1 Troika: Getting Started
Introduction
As software tools for exploring and developing transformer applications, few platforms can top a Google Colab and Hugging Face combo. Together they make for an effective, convenient and low cost way to do serious work with machine learning models. Familiarity with the two systems is key to using them together to accomplish a particular ML task.
Did I say that Colab and Hugging Face are free to use? Anyone with a Google account can access the free-tier Jupyter system hosted in the Colab cloud. Similarly, all it takes is an email address to sign up for Hugging Face and join the many machine learning practitioners collaborating in that community with genuine open source verve.
In this blog post, I show the steps to get up and running with Colab and Hugging Face Hub. I’ll talk about the authentication required to access gated models hosted at Hugging Face. Using llama3.1 as an example, I’ll also show how to use the transformer model to tokenize an input string, thereby validating our access of the model within a Colab notebook.
Gated Models and Access Tokens
The Hugging Face Hub is a registry for a variety of machine learning models made public by their creators. To exercise control over the models they’ve shared, a number of these authors screen access, requiring users to register their Hugging Face account as prerequisite. Once an application has been submitted, waiting for approval may take up to a few hours.
meta-llama/Meta-Llama-3.1-8B is one such restricted repository. Visiting the model’s card at Hugging Face Hub, we see the banner below.
Much like trading cards in a game, a Hugging Face card is standardized way to present information about a particular model. Starting with a template, model creators create a web page with static and dynamic components that, taken together, portrays various technical aspects of an ML model.
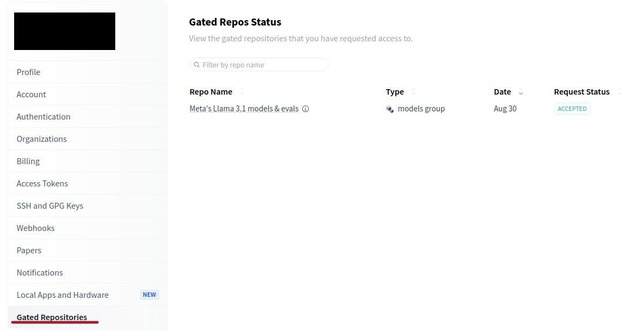
We look into the Settings panel of our Hugging Face account to check the status of our access to gated repositories. The image below indicates that a request to meta-llama/Meta-Llama-3.1-8B has been approved.
Apart from securing access to a gated model, a Hugging Face user access token is another thing we’ll need for interacting with llama3.1 within a Colab notebook.
See this article on Hugging Face for steps to create a user access token.
As its name implies, a user access token determines the degree of access an application has to the resources of a Hugging Face account. There are three types of tokens: fine-grained; read only; and write only. When it comes to creating a new token, fine-grained ones are the most involved in that access to every aspect of a Hugging Face account can be toggled on or off. Read- and write-only tokens are much simpler. For the purpose of this exercise, we use a read-only token in our Colab notebook to interact with llama3.1.
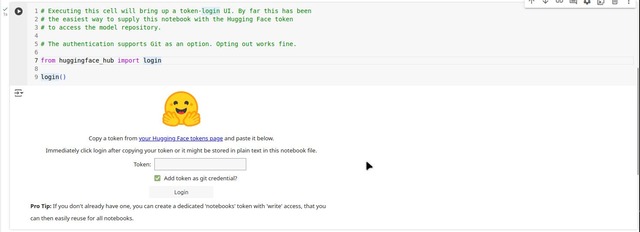
A token is long text string beginning with hf_. In Colab we can export it as an environment variable. Alternately, Colab Secrets is feature that securely handles sensitive data such as a Hugging Face token. But instead of using these two methods, we’ll embed a Hugging Face API call that issues a token challenge as our Colab notebook executes.
Transformers and Tokenizers
As NLP tools, transformer models such as llama3.1 ingest text strings. By a process called tokenization, they map units of text to integers. This mapping constitutes the vocabulary of a model. The tokenizer breaks down an input text string into individual characters for use to reconstitute whole or sub-words.
Transformers is a Python package sponsored by Hugging Face. In the early days of ML research into deep learning, developers lacked a standard framework for the pre-trained models they made public. With the Transformer package, and the larger Hugging Face ecosystem, DL practitioners now benefit from a common scaffolding they can build their work upon.
Given that words in the text can include declinations and conjugations – even misspellings – we’re quickly faced with the problem of an outsized vocabulary that balloons the size of a model’s parameters. To keep things manageable, transformer models are trained to recognize a set of commonly used words, with unknown or misspelled tokens dealt as sub-word fragments.
For example, here is the output of the llama3.1 tokenizer ingesting the text string “Hunger is the best sauce in the world.” Also “Virtue is persecuted by the wicked more than it is loved by the good.” The Ġ character indicates a space that precedes the token, a marker that the sequential sub-words such as 'H' and 'unger' lack.
Quotes taken from Cervantes’ Don Quixote.
{'input_ids': [128000, 39, 72722, 374, 279, 1888, 19737, 304, 279, 1917, 13], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
['<|begin_of_text|>', 'H', 'unger', 'Ġis', 'Ġthe', 'Ġbest', 'Ġsauce', 'Ġin', 'Ġthe', 'Ġworld', '.']
<|begin_of_text|>Hunger is the best sauce in the world.
{'input_ids': [128000, 53, 2154, 361, 374, 93698, 555, 279, 45077, 810, 1109, 433, 374, 10456, 555, 279, 1695, 13], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
['<|begin_of_text|>', 'V', 'irt', 'ue', 'Ġis', 'Ġpersecuted', 'Ġby', 'Ġthe', 'Ġwicked', 'Ġmore', 'Ġthan', 'Ġit', 'Ġis', 'Ġloved', 'Ġby', 'Ġthe', 'Ġgood', '.']
<|begin_of_text|>Virtue is persecuted by the wicked more than it is loved by the good.Putting It All Together
Once we have the user account token in hand, and once we receive the permission to access meta-llama/Meta-Llama-3.1-8B housed in Hugging Face Hub, all that’s left is to code the Jupyter notebook in Google Colab.
# May not need this unless Colab throws errors regarding llama3.1 Python packages.
!pip install --upgrade transformers# Primarily for Hugging Face authentication.
!pip install huggingface_hub# Executing this cell will bring up a token-login UI. By far this has been
# the easiest way to supply this notebook with the Hugging Face token
# to access the model repository.
# The authentication supports Git as an option. Opting out works fine.
from huggingface_hub import login
login()When the above cell is executed, Colab prompts us to supply the user access token. To keep things simple, we can deselect the git option.
import transformers
import torch
from transformers import AutoTokenizer
model_id = "meta-llama/Meta-Llama-3.1-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)It’s worth nothing that running the above cell fetches the token mapping that llama3.1 uses. Colab will cue us to this by means of bars that mark the download progress.
# Quote from Cervantes' "Don Quixote".
text = "Hunger is the best sauce in the world."
encoded_text = tokenizer(text)
print(encoded_text)
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
print(tokenizer.convert_tokens_to_string(tokens))The output is simply the one I discussed in the section above regarding tokenization, presenting the word and sub-words of the tokens and their numerical mapping. The output validates this simple exercise of using meta-llama/Meta-Llama-3.1-8B in a Google Colab notebook.